|
|
Common Mistakes Made with Golang, and Resources to Learn From
Background: My Experience with Golang Thus Far
I’ve been keeping tabs on Go for a while now, so I was excited when a couple of months ago I had the need to serve millions of hits from a small grouping of dedicated servers, which needed to:
- Cache requests for a pre-determined TTL
- Reach out to my database (Cassandra with a cluster in the same Data Center)
- Return a JSON marshalled response for any given endpoint
In ideally under 10ms. I architected a solution which relied heavily on Go:
Caching
After mentioning that I was thinking of using Redis (being used in conjunction
with twemproxy,
smitty, and
Redis Sentinel) as read-only storage for
the endpoint data, #go-nuts user kaos` on freenode suggested that
I eat “mashed glass”.
With a more fruitful discussion with user Tv`, I’d stumbled across - and ended up using - Groupcache, which I’m using with a user-defined TTL.
I’ll go over the great benefits of using Groupcache soon in another post!
Web Serving
Initially, since I only wanted to get one endpoint up and running, I’d decided on simply using Go’s incredible net/http core Package.
It’s quick and provides all of the functionality a simple API would need.
Data Access
Quickly and efficiently accessing the data from Groupcache was easy thanks to another core Go Package: net/rpc.
A Remote Procedure Call is an incredibly powerful technique for using functions made publicly available on another server’s API.

source: [http://www.cs.cf.ac.uk/Dave/C/node33.html](http://www.cs.cf.ac.uk/Dave/C/node33.html)
Production
As I was working on and writing a number of other moving parts for this particular project, I’d asked a great colleague of mine, Kurt Froehlich, to put together a working Webserver and Data Access backend using the above architecture. Overall, I’d say the process went smooth since I’d found a full example which (albeit in a little bit of an obfuscated manner) hits all three points needed.
At a very high level, most of what was needed was achievable by replacing the slowdb with Cassandra by way of using the gocql Cassandra Client, and writing a few methods to retrieve and format incoming query parameters as we needed them.
Kurt was able to get this running and separated into different packages within a week or two with minimal prior knowledge of the language. I think he’d made it about 80 pages into Programming in Go when he’d started working on it. Definitely a testament to both Kurt and the ease of using/learning Go.
I’ve since patched a few performance pitfalls in the code, rewritten the API to use the mux Package from the Gorilla web toolkit, and expanded the API to a number of endpoints. But, the core of the original functionality is still much the same, and it runs great.
Additionally, I’d written ~2k LOC in Go for data ingestion, retrieval, and reporting in different areas of this application. One of the first (and only publicly available) pieces I’d written is a script named solr-fetch which fetches and downloads all the pieces of the latest version of a Apache Solr index via the Solr REST API.
So, Common Mistakes…
Recently, over in /r/golang, I’ve seen an influx of posts about issues people have when they use constructs that they might not fully understand or have not understood what the consequences of using them are, like:
So I figured I’d go over a few resources on where to best fill this
understanding gap if you want to bypass some of these issues. If you have any
specific questions, shoot me an email at mo [at] umkr.com, and I’ll see if I
can either answer them or find some resources which do.
(Non)Persistent Connections
One of the easiest pitfalls to stumble into when using any external resource is the latency and load associated with creating and closing new connections.
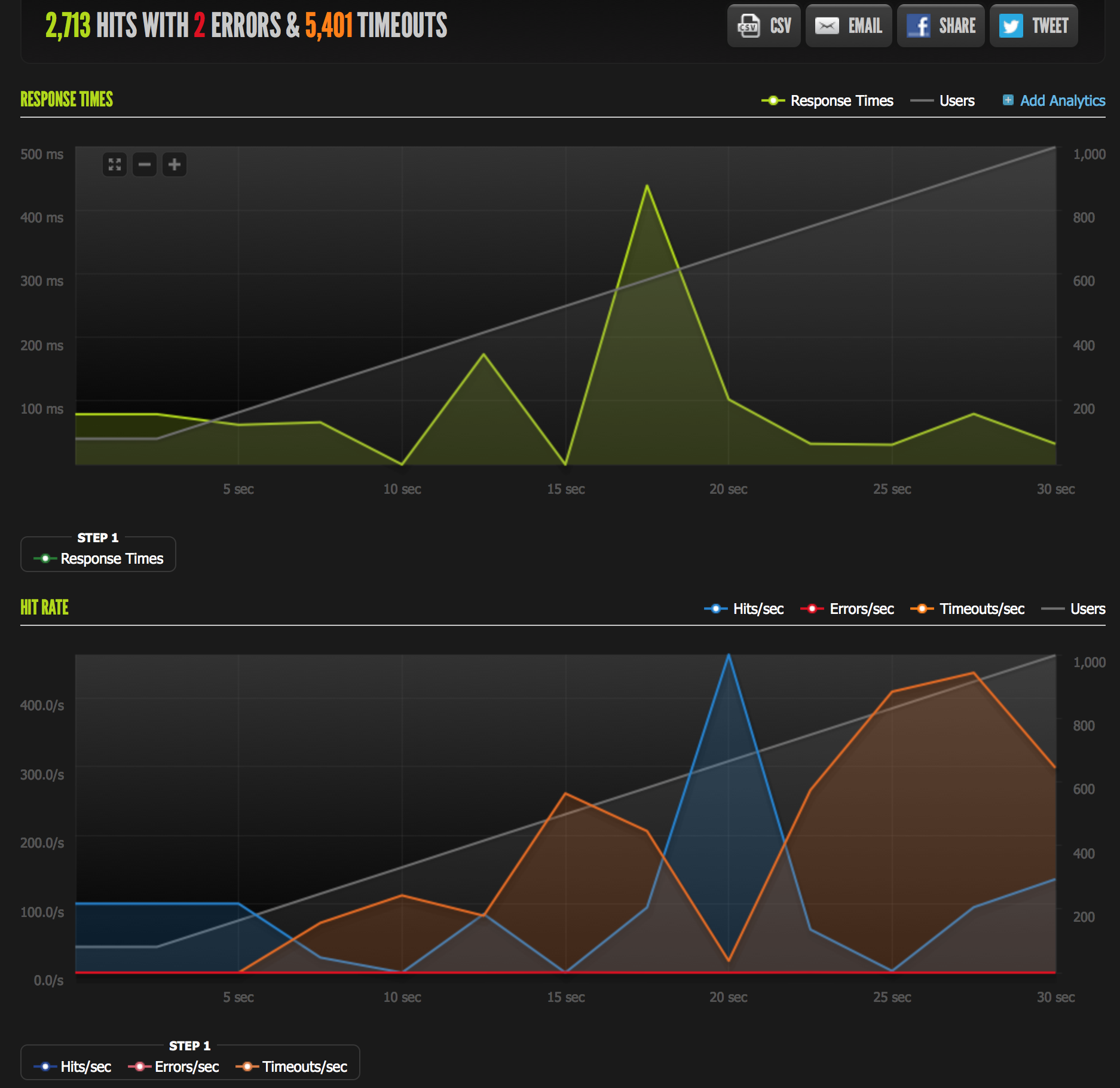
In the above project, the initial implementation created and closed an RPC connection on every request. As the number of requests scaled up, this quickly caused both the Data Access RPC Server and the Webserver to stumble over themselves, as we can see here:
So, what’s the solution? Well, if we look closely at the relevant areas of the
net/rpc Package source code, we can see that a
single connection is already built to handle many concurrent requests with the
rpc.Client.Go method.
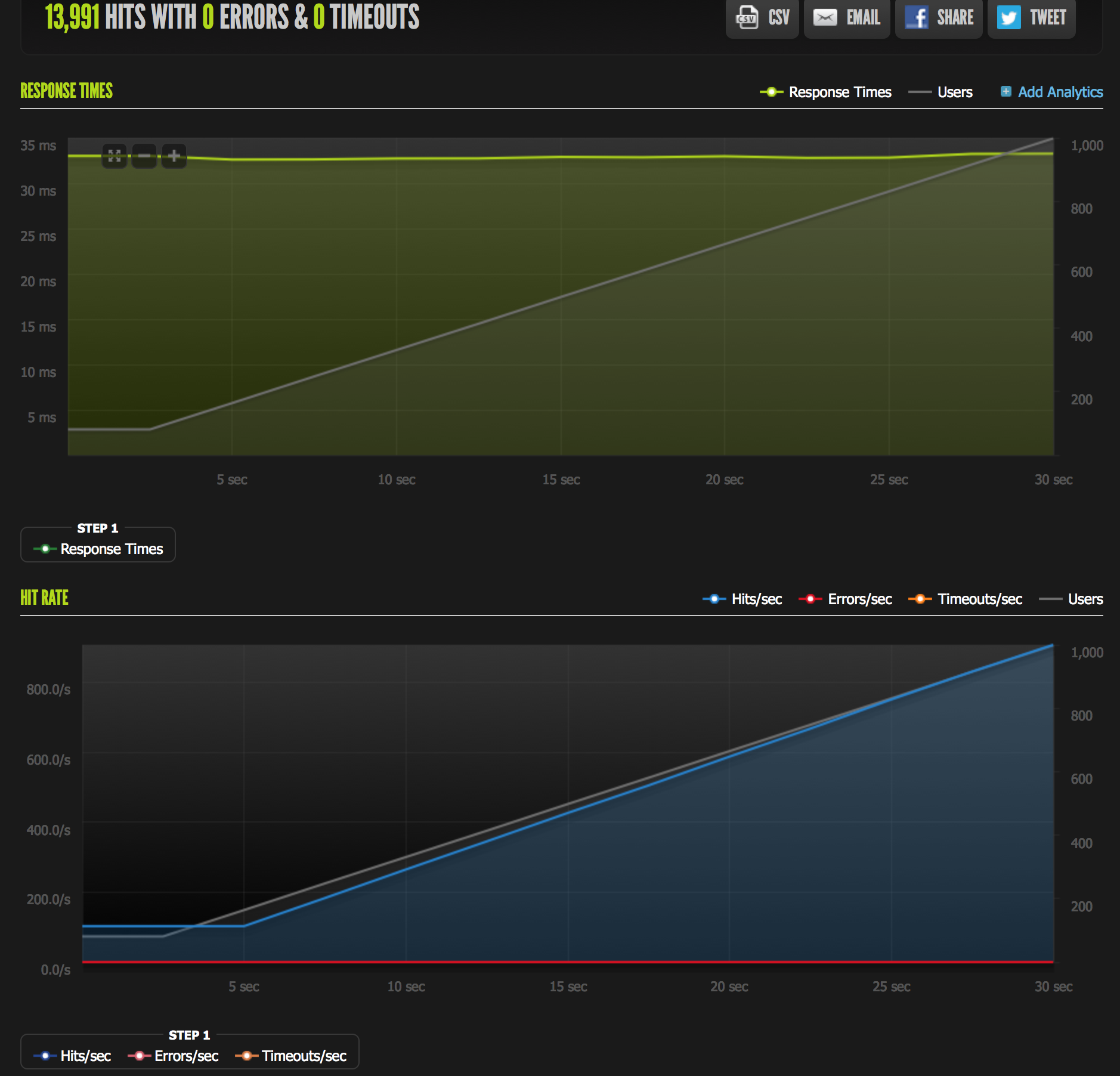
I moved the RPC Client to a global variable, so that every Goroutine can make use of the same connection, and added a very basic connection maintenance pattern. This could be improved further with connection pools etc. In any case, we’re able to see that built-in concurrency at work:
Performance differences for a stress test ranging from 0 - 1000 concurrent users:
- Average response time decreased from 110ms to 32ms
- Maximum response time decreased from 438ms to < 33ms
- Total number of timeouts decreased from 5401 to 0
- Total number of errors decreased from 2 to 0
- Total number of hits processed increased from 2713 to 13,991
Growing fat from leftovers
Goroutines are cheap. Their minimum stack size is only 8kb. This is why we can create thousands of them and not sweat it.
Unless.
Unless you’re making use of functions that make use – and return values from –
slices. I’d run into this just a few weeks ago, as I had written a couple of
functions without bearing in mind the inner workings of the Slice.
As described on this Go Blog post about slices, reslicing an array doesn’t make a copy of the original, underlying, array for a given slice - it just continues to use the original array until nothing references it.
If you find yourself creating a large slice within a function used by a
Goroutine, but only returning a single item from the slice
(ie: return mySlice[1:4]), bear in mind that the entire array that your
original slice references is still in memory!
Do this n number of times, and you could quickly find yourself depleting the
memory available to new goroutine stacks. Try to create one more under these
conditions, and your program will start spitting up errors.
Loops, Closures, and Local Variables
The Go documentation has a great article about this common mistake in particular, so I won’t reproduce the entire explanation here.
The premise is that when iterating over a loop, if you fire off a goroutine for each item in the loop and pass it a reference to the variable which is changing in the loop, each goroutine will be referencing the same variable.
Mistake
|
|
Directly from the referenced article, “By adding val as a parameter to the closure, val is evaluated at each iteration and placed on the stack for the goroutine, so each slice element is available to the goroutine when it is eventually executed.” We can see that in action here:
Corrected
|
|
Concurrency, Channels, Completion
At the beginning of the article I’d linked to a blog post about a “go concurrency bug” that a user had “inflicted upon [himself].”
My major gripe with this article was that using Channels and Goroutines can be very easy and enjoyable if you understand how they work. The solution presented in the article does work, but it doesn’t address a very basic principle: Goroutines run on their own; unless you explicitly wait for them to finish, your main thread will continue executing as normal.
Take that thought and keep it in the back of your mind whenever you use Channels and Goroutines.
There are many patterns to productively work with - and ensure the completion of work from - Channels and Goroutines, or just Goroutines on their own.
Many are described in this Go blog post about Pipelines and this Google I/O 2013 presentation about Advanced Go Concurrency Patterns.
Dealing with race conditions doesn’t have to be painful, either. Go’s 1.1 release included the Go Race Detector, also described in the Go Blog Post: Introducing the Race Detector.
// Source: https://code.google.com/p/go-wiki/wiki/CommonMistakes for val := range values { go func() { fmt.Println(val) }() }